
- Technology companies are expected to exhaust the supply of publicly available training data for AI language models between 2026 and 2032, according to a new study published by research group Epoch AI.
- When public data eventually runs out, developers must decide what to feed their language models. Ideas include data that is now considered private, such as emails or text messages, and using “synthetic data” generated by other AI models.
- In addition to training larger and larger models, another path to pursue is building more skilled training models specialized for specific tasks.
Artificial intelligence systems like ChatGPT may soon run out of what makes them smarter at the trillions of words people write and share online.
Technology companies are expected to exhaust the supply of publicly available training data for AI language models between roughly 2026 and 2032, according to a new study published Thursday by research group Epoch AI.
Tamay Besiroglu, the study's author, likened this to a “literal gold rush” depleting finite natural resources, adding that the field of AI will likely slow down its current pace of progress if it depletes its reserves of human-generated writing. He said it could be difficult to maintain.
Yellen acknowledges 'tremendous opportunity' but warns of 'significant risks' in financial AI
In the short term, tech companies like ChatGPT maker OpenAI and Google are competing to secure, and sometimes pay for, high-quality data sources to train AI large-scale language models. On Reddit forums and news media outlets.
In the long term, there will not be enough new blogs, news articles, and social media commentary to sustain the current trajectory of AI development, putting pressure on companies to leverage sensitive data currently considered private, such as emails and text messages. It relies on less reliable “synthetic data” spit out by the chatbot itself.
“There is a serious bottleneck here,” Besiroglu said. “Once you start hitting constraints on the amount of data you have, you can no longer scale your model efficiently. And model scaling has probably been the most important way to scale functionality and improve output quality.”
Artificial intelligence systems like ChatGPT are consuming ever-increasing collections of human writing to become smarter. (AP Digital Insert)
Researchers first made the prediction two years ago (just before ChatGPT debuted) in a working paper predicting a more imminent 2026 disruption of high-quality text data. A lot has changed since then, including new techniques that allow AI researchers to make better use of the data they already have and to “overtrain,” sometimes multiple times on the same sources.
However, there are limitations, and with further research, Epoch now predicts that open text data will be depleted within the next two to eight years.
The team's latest research has been peer-reviewed and will be presented at the International Conference on Machine Learning in Vienna, Austria this summer. Epoch is a non-profit organization hosted by San Francisco-based Rethink Priorities and funded by supporters of Effective Altruism, a philanthropic movement committed to mitigating the worst risks of AI.
Besiroglu said AI researchers realized more than a decade ago that they could significantly improve the performance of AI systems by aggressively scaling two key factors: computing power and massive Internet data storage.
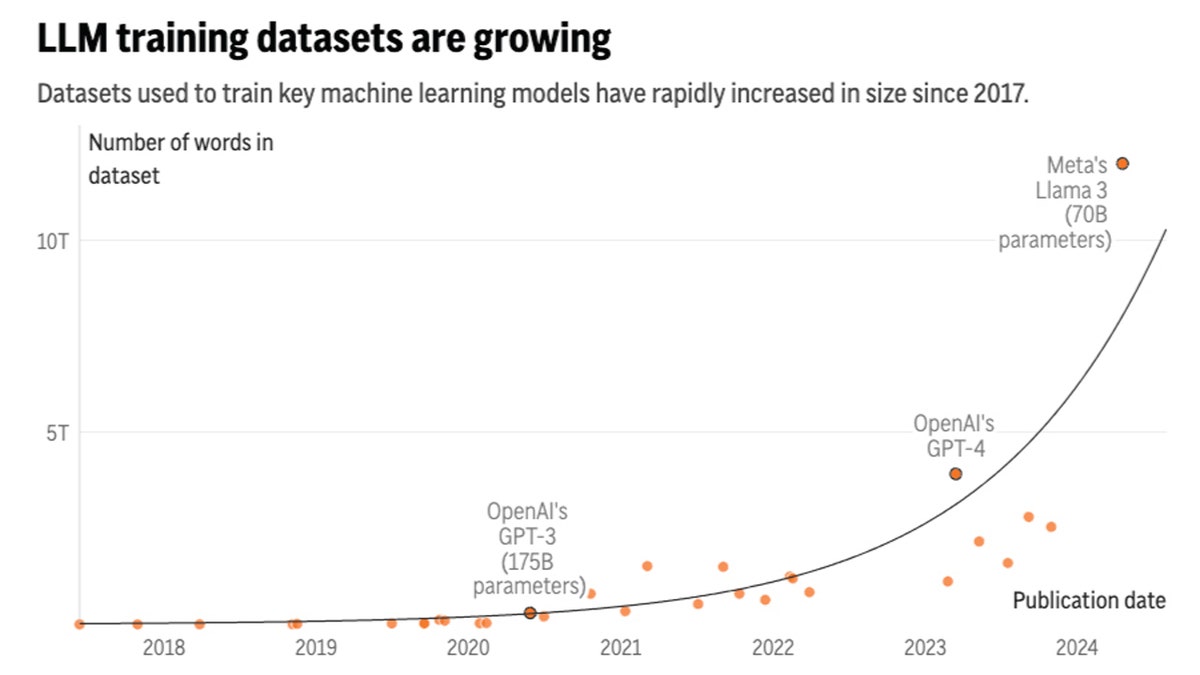
According to Epoch research, the amount of text data input to AI language models has grown approximately 2.5 times per year, while computing has increased approximately 4 times per year. Facebook's parent company, Meta Platforms, recently claimed that the largest version of its upcoming Llama 3 model (not yet released) has been trained on up to 15 trillion tokens that can represent a single word fragment.
However, it is debatable how much data bottlenecks are worth worrying about.
“I think it’s important to keep in mind that you don’t necessarily need to train a larger model,” said Nicolas Papernot, an assistant professor of computer science at the University of Toronto and a researcher at the non-profit Vector Artificial Intelligence Institute.
Building more skilled AI systems could also come from training models that are more specialized for specific tasks, said Papernot, who was not involved in the Epoch study. However, he is concerned that the resulting AI systems will be trained on the same output they produce, leading to a performance degradation known as “model collapse.”
7 notable things Google recently announced
Training on AI-generated data is “like what happens when you copy a piece of paper and then copy that copy — you lose some information,” Papernot said. What's more, Papernot's research shows that it can encode more of the mistakes, biases, and unfairness that are already ingrained in the information ecosystem.
If actual human-generated sentences remain an important source of AI data, those who manage the most popular information – websites like Reddit, Wikipedia, news and book publishers – will have to think hard about how these sentences come into existence. It is being used.
“It’s probably not going to cut off the top of every mountain,” jokes Selena Deckelmann, chief product and technology officer at the Wikimedia Foundation, which runs Wikipedia. “It’s an interesting issue right now that we’re having a conversation about human-generated data about natural resources,” she said. “I can’t laugh, but I think it’s really amazing.”
While some have tried to block data from AI training after it has already been pulled without compensation, Wikipedia places few restrictions on how AI companies can use entries written by volunteers. Still, Deckelmann said he hopes there will continue to be incentives for people to keep contributing, especially as a flood of cheap, automatically generated “junk content” begins to pollute the Internet.
AI companies “must be concerned about how human-generated content continues to exist and remain accessible,” she said.
From the perspective of AI developers, Epoch's research suggests that paying millions of humans to generate the text needed by AI models is “probably not an economical way” to drive better technical performance.
CLICK HERE TO GET THE FOX NEWS APP
As OpenAI begins work on training its next-generation GPT large language model, CEO Sam Altman told an audience at a United Nations event last month that the company has already experimented with “generating a lot of synthetic data” for training.
“I think what we need is high-quality data. We have low-quality synthetic data. We also have low-quality human data,” Altman said. But he also expressed reservations about relying too heavily on synthetic data rather than other technological methods to improve AI models.
“It would be very strange if the best way to train a model was to generate hundreds of billions of synthetic data tokens and feed them back,” Altman said. “Somehow that seems inefficient.”